- Emergent Behavior
- Posts
- Teaching Robots To Do Stuff
Teaching Robots To Do Stuff
Berkeley-UW-Stanford team project allows allow robots to learn by real-world attempts by figuring out how to accomplish the task using any kind of minimally specced robot
Prakash Ate-A-Pi
January 31, 2024
🔷 Subscribe to get breakdowns of the most important developments in AI in your inbox every morning.

What’s the biggest problem in robotics? If you want to train them, you need real-world data… and current methods which would require say a robot to attempt to plug a power cord in 10,000 times in order to learn how to do it, are just too expensive in the real world.
This Berkeley-UW-Stanford team decided to solve this by:
putting together an out-of-the-box software stack for getting reinforcement learning running on robots
putting together the best pieces for algorithms, rewards and resets; with
minimal hardware specifications for controllers that work well for contact-based manipulation tasks
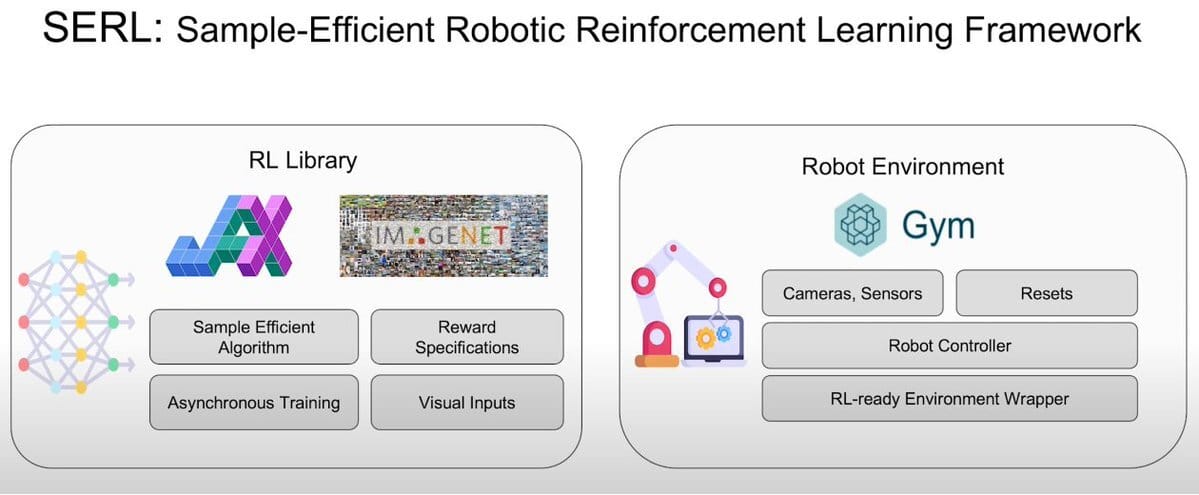
Reinforcement Learning Library and the Robot Environment
The overall intent of the project is to allow robots to learn by real-world attempts, and making this economically feasible by reducing the number of attempts required to carry out the task. Given that a small number of attempts are sufficient, finely tuned hardware is de-emphasized, meaning that instead of building software that will work perfectly with a particular robot, we allow the learning to figure out how to accomplish the task using any kind of minimally specced robot.
The results of this work are spectacular, using the SERL package:
University of Washington team were able to print 3D pegs
Setup the hardware and software
Insert the pegs into a board using a robot arm
Achieve 100% success rate with 20 initial human demonstrations
Within 19 minutes
End to end including setup took less than 3 hours
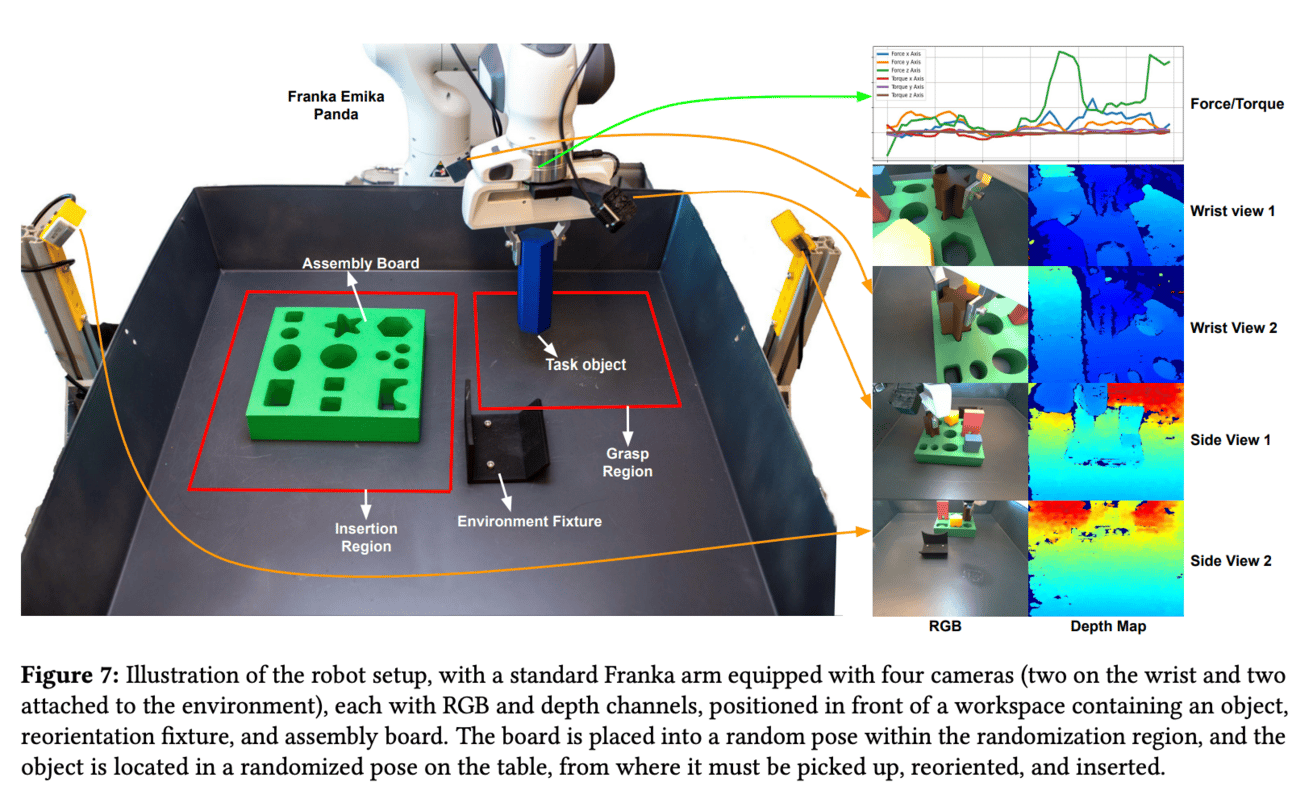
Notably:
they use a simple image classifier to detect whether the robot has completed the task successfully, avoiding complex perception systems completely
they defined a “reset” mechanism so that the robotic arm could say remove the peg it had already inserted and return to the start point, as current practice is often to have a human intervene to reset for the next attempt
the system is robust, you can rearrange the setting, and even mess with the robot during the attempt (perturbation)
The amazing part of all of this is that it’s just vision + learning. Instead of training on a complex sensor fusion datastream from the robot, the training is done just on raw images, with the neural network figuring out how to use the robot to achieve the results desired as per the reward algo.
This process notably produced a pre-trained language model which was both more efficient and more competent.

Become a subscriber for daily breakdowns of what’s happening in the AI world:
Reply